
Welcome
ITU Artificial Intelligence/Machine Learning in 5G Challenge

North Carolina State University invites you to participate in the ML5G-PHY [channel estimation] challenge, which is part of the ITU Artificial Intelligence/Machine Learning in 5G Challenge, a competition that is scheduled to run from now until the end of the year. Participation in the Challenge is free of charge and open to all interested parties from countries that are members of ITU. Detailed information about the motivation for this competition can be found on the Challenge website, which includes the document “ITU AI/ML 5G Challenge – Applying AI/ML in 5G networks. A Primer”.
In the subsequent sections, we present the details of our challenge, “Machine Learning Applied to the Physical Layer of Millimeter-Wave MIMO Systems [channel estimation]” at North Carolina State University (ML5G-PHY [channel estimation]), which is based on Raymobtime datasets.
The ML5G-PHY channel estimation challenge attacks one of the most difficult problems in the 5G physical layer: acquiring channel information to establish a millimeter wave MIMO link (initial access) considering a hybrid MIMO architecture. Approaches in the challenge will lead to important insights into what can be achieved using data-driven and/or model-based approaches.
Participants are encouraged to design either a ML-based approach or a more conventional signal processing algorithm that can learn some priors from the provided training data set to provide high accuracy channel estimates with low training overhead during the testing phase.
Challenge: Site-specific channel estimation with hybrid MIMO architectures
In our site-specific channel estimation challenge, we focus on the uplink channel estimation problem. A set of training channels and training received pilots specific for the area covered by a given base station (BS) are available during off-line training. These data sets can be used either to train a given network or to learn priors that can be leveraged by a conventional algorithm, such as AoA/AoD distributions, possible sparsity patterns, etc. In the testing phase, a different set of channels, still corresponding to the same site, will be used to evaluate the performance of the proposed approaches.The acquired data will correspond to a frequency selective hybrid millimeter wave MIMO-OFDM system as described in [1]–[4], where both the transmitter and receiver are equipped with a hybrid architecture as in Figure 1. The precoders and combiners are hybrid, splitting the processing into an analog and a digital stage. The system operates with uniform linear arrays (ULAs) at both ends. In particular, we consider a transmitter at the user equipment (UE) side with Nt=16 antennas and Lt=2 RF chains; the receiver at the BS has Nr=64 antennas and Lr=4 RF chains. The number of streams to be transmitted is set as Ns=2. The MIMO-OFDM system operates with K=256. The mmWave channel is assumed to be frequency selective.
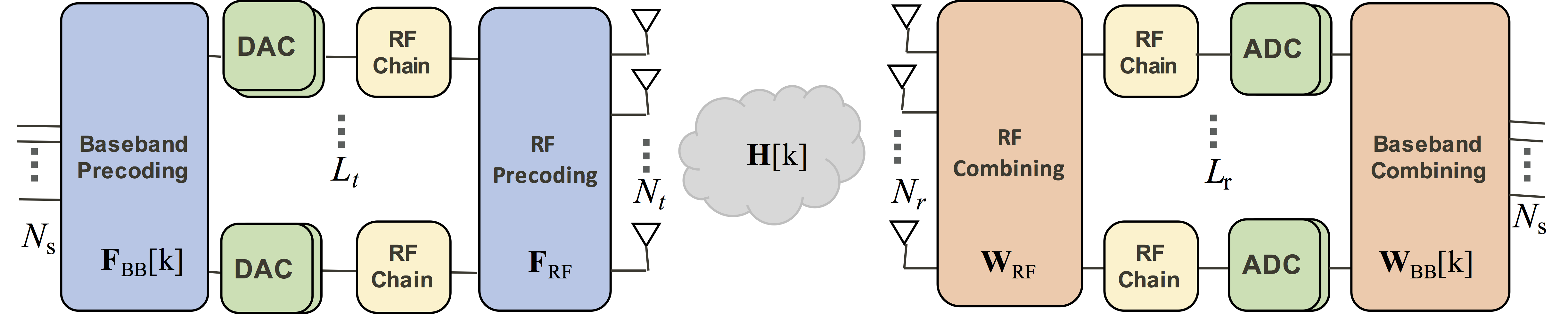
We define a training pilot as an OFDM symbol known at both the TX and the RX. The challenge consists of estimating the frequency selective MIMO channel at low SNR from a low number of received training pilots. ML-based solutions or any type of conventional approach that exploits millimeter wave channel sparsity can be submitted as a proposed solution to the challenge. Note that conventional algorithms can also use the training data to learn any type of prior to be leveraged by the proposed algorithm. For example, in [5], online learning is used to obtain the AoD statistics at a BS and design a compressed sensing matrix for compressive beam alignment.
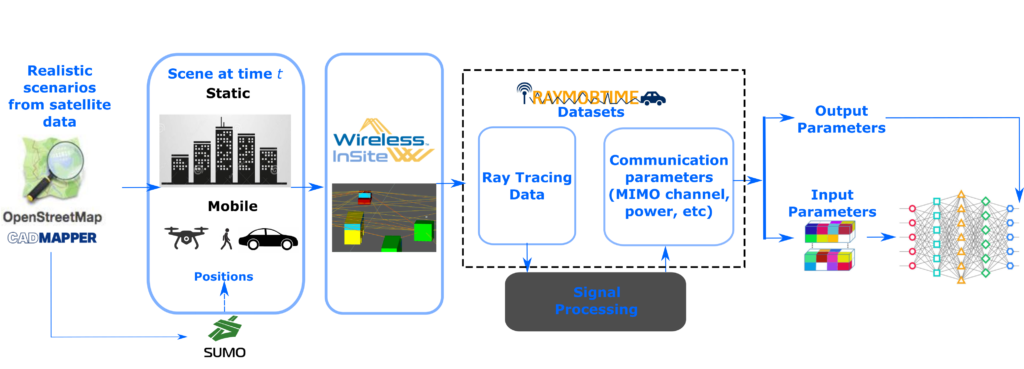
The Channel Training Dataset that we provide here consist of a collection of 10,000 channels in HDF5 format obtained from Raymobtime dataset s004, generated at the servers at UFPA and UT Austin hosted by the research groups coordinated by Prof. Aldebaro Klautau, Prof. Robert Heath and Prof. Nuria González-Prelcic (last two faculty members now at NC State University). Raymobtime data sets are generated by ray tracing. The methodology used to generate the channels is summarized in Figure 2 and described in detail in [6].
Participants have to train their networks using 100 received pilots in the frequency domain for each one of the provided channels. To generate the pilots, we provide a Matlab implementation of the previously described MIMO-OFDM system, which considers analog-only pseudorandom precoders and combiners during training as described in [1], [2]. The Matlab code can be downloaded here. The script to be executed is “gen_RXtraining_SNR_Raymobtime”. The script allows to load or save data in MAT or HDF5 files. The second script, “gen_channel_ray_tracing rev” creates the MIMO channel matrices from the ray tracing channels in the training data set. It is called by “gen_RXtraining_SNR_Raymobtime”. Please, note that this second script had been revised.
Using the provided code and the Channel Training Dataset, participants should generate three training datasets containing the received pilots for SNR=-15dB, -10 dB, and -5 dB. Each training set corresponds to a given SNR. Thus, Training Dataset 1 corresponds to SNR=-15 dB; Training Dataset 2 corresponds to SNR=-10 dB, and Training Dataset 3 corresponds to -5 dB. Participants only have to set up the parameter called data_set in the provided script to 1, 2 or 3. By doing this, the code initializes the SNR and the file name that stores the received training symbols to their corresponding values.
As test datasets, we provide 9 collections of received pilots obtained at SNRs ranging from -20 to 0 dB and 1000 channels different from the ones in the training datasets, but corresponding to the same site. We also provide the corresponding sets of pilot symbols, and associated precoders and combiners. The channels corresponding to these pilots will not be available. To be able to understand the trade-off accuracy-overhead provided by a given approach, we generated nine different test datasets that contain a different number of received pilots per test channel.
- Test Dataset 1 SNR1 contains 20 received pilots for each one of the considered test channels when the SNR is in the range [-20dB,-11dB[.
- Pilots, precoders and combiners for Test Dataset1 SNR1, contains the 20 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 1 SNR2 contains 20 received pilots for each one of the considered test channels when the SNR is in the range [-11dB,-6dB[.
- Pilots, precoders and combiners for Test Dataset1 SNR2, contains the 20 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 1 SNR3 contains 20 received pilots for each one of the considered test channels when the SNR is in the range [-6dB,0dB].
- Pilots, precoders and combiners for Test Dataset1 SNR3, contains the 20 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 2 SNR1 contains 40 received pilots for each one of the considered test channels when the SNR is in the range [-20dB,-11dB[.
- Pilots, precoders and combiners for Test Dataset2 SNR1, contains the 40 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 2 SNR2 contains 40 received pilots for each one of the considered test channels when the SNR is in the range [-11dB,-6dB[.
- Pilots, precoders and combiners for Test Dataset2 SNR2, contains the 40 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 2 SNR3 contains 20 received pilots for each one of the considered test channels when the SNR is in the range [-6dB,0dB].
- Pilots, precoders and combiners for Test Dataset2 SNR3, contains the 40 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 3 SNR1 contains 80 received pilots for each one of the considered test channels when the SNR is in the range [-20dB,-11dB[.
- Pilots, precoders and combiners for Test Dataset3 SNR1, contains the 80 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 3 SNR2 contains 80 received pilots for each one of the considered test channels when the SNR is in the range [-11dB,-6dB[.
- Pilots, precoders and combiners for Test Dataset3 SNR2, contains the 80 pilots per TX RF chain, and their corresponding precoders and combiners.
- Test Dataset 3 SNR3 contains 80 received pilots for each one of the considered test channels when the SNR is in the range [-6dB,0dB].
- Pilots, precoders and combiners for Test Dataset3 SNR3, contains the 80 pilots per TX RF chain, and their corresponding precoders and combiners.
To evaluate the different approaches proposed by the participants, we consider the normalized mean square error (NMSE) in the channel estimates as basic metric. To obtain a final score we weight the obtained NMSE in a different way depending on the SNR range and training length, giving more weight to the more challenging settings (lower SNR and less training). This way, the final performance score (PS) is obtained as:
PS=0.5(0.5NMSE(Test Dataset 1 SNR1)+0.3NMSE(Test Dataset 1 SNR2)+0.2NMSE(Test Dataset 1 SNR3))
+ 0.3(0.5 NMSE(Test Dataset 2 SNR1+0.3 NMSE(Test Dataset 2 SNR2)+0.2NMSE(Test Dataset 2 SNR3))
+ 0.2(0.5 NMSE(Test Dataset 3 SNR1)+0.3 NMSE(Test Dataset 3 SNR2)+0.2NMSE(Test Dataset 3 SNR3))
Models must be trained only with examples included in the provided datasets. It is not allowed to use additional data extracted from other datasets.
You can participate in teams. The team members should be announced at the enrollment stage and will be considered to have an equal contribution.
The participants have to submit a brief document (up to 5 pages) in English describing the proposed approach, the source code of the proposed solution and the estimated channels following the same format as in the Test Datasets. In particular, we require nine files containing the estimated channels for the nine Test Datasets. The provided information and models must allow us to replicate the reported results.
Registration → July 31, 2020, defined by ITU
Submission (Global round) → October 2020, to be defined by ITU
Award (Global round) → October 2020, to be defined by ITU
All participants of the ML5G-PHY [channel estimation] task are required to register at the ITU website before July 31, 2020, and also enroll the teams by sending an email to ml5gphy.ncsu@gmail.com. We will send a confirmation email for team enrollment in a few hours. In the email, inform the team name, the name of each participant (recall that each one must have registered individually at the mentioned ITU website), and an email for contact (if not the email used for enrollment).
Also, all participants are strongly encouraged to join the ITU Challenge slack channel https://itu-challenge.slack.com for announcements and questions/comments. Instructions to join the Slack channel are available at https://join.slack.com/t/itu-challenge/shared_invite/zt-eql00z05-CXelo7_aL0nHGM7xDDvTmA.

[1] J. Rodríguez-Fernández, N. González-Prelcic, K. Venugopal and R. W. Heath, “Frequency-Domain Compressive Channel Estimation for Frequency-Selective Hybrid Millimeter Wave MIMO Systems,” IEEE Transactions on Wireless Communications, vol. 17, no. 5, pp. 2946-2960, May 2018.
[2] J. P. González-Coma, J. Rodríguez-Fernández, N. González-Prelcic, L. Castedo and R. W. Heath, “Channel Estimation and Hybrid Precoding for Frequency Selective Multiuser mmWave MIMO Systems,” IEEE Journal of Selected Topics in Signal Processing, vol. 12, no. 2, pp. 353-367, May 2018
[3] C. K. Anjinappa, A. C. Gurbuz, Y. Yapici and İ. Güvenç, “Off-Grid Aware Channel and Covariance Estimation in mmWave Networks,” IEEE Transactions on Communications, Mar. 2020 (Early Access).
[4] M. Ruble and I. Güvenç, “Multilinear SVD for Millimeter Wave Channel Parameter Estimation,” IEEE Access, vol. 8, pp. 75592-75606, Apr. 2020.
[5] Y. Wang, N. Jonathan Myers, N. Gonzalez-Prelcic, and Robert W. Heath Jr., “Site-specific online compressive beam codebook learning in mmWave vehicular communication,” submitted to IEEE Transactions on Wireless Communications, May 2020, available in arXiv.
[6] A. Klautau, P. Batista, N. González-Prelcic, Y. Wang and R. W. Heath, “5G MIMO Data for Machine Learning: Application to Beam-Selection Using Deep Learning,” in Proc. of the Information Theory and Applications Workshop (ITA), San Diego, CA, 2018, pp. 1-9.