
Towards Interpretable Object Detection by Unfolding Latent Structures (Oral presentation)
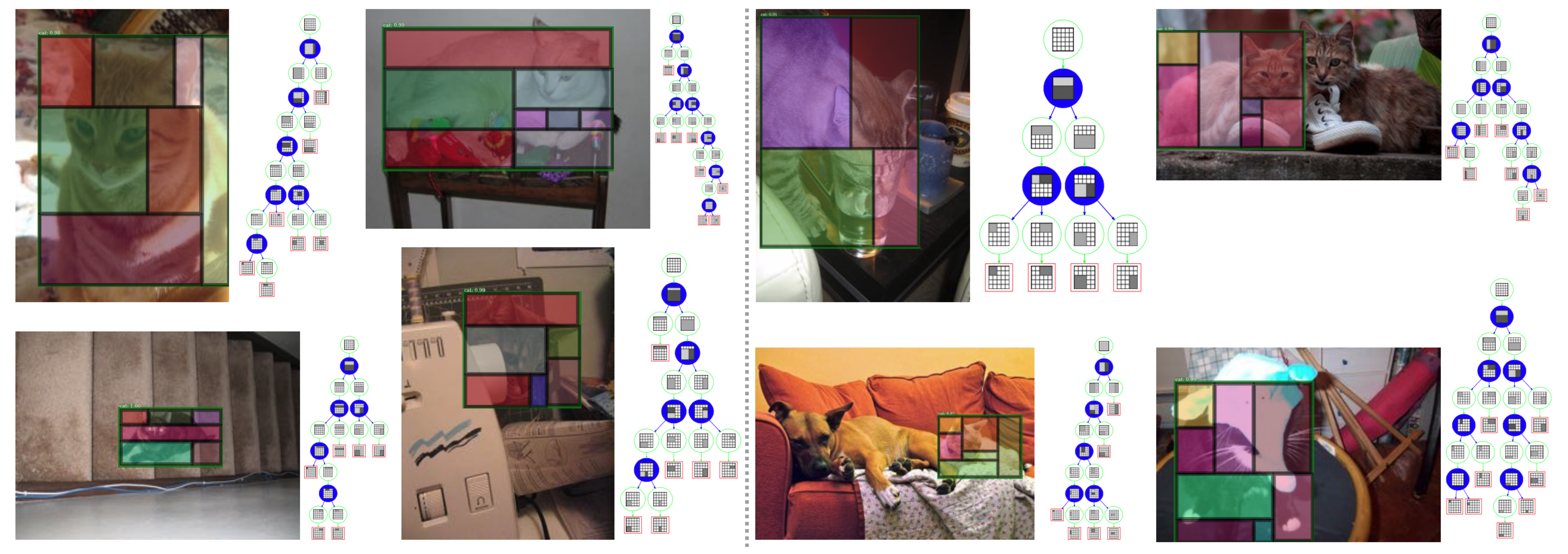
Why are those bound boxes detected as cats? Illustration of qualitatively interpreting model interpretability via unfolding latent structures end-to-end without any supervision used in training. Latent structures are represented by parse trees (shown to the right of each image) computed on-the-fly and object layouts/configurations (superposed on the bounding boxes) are collapsed from the parse trees. The left four images are from PASCAL VOC2007 test dataset and the right four ones from the COCO val2017 dataset. For clarity, only one detected object instance is shown.
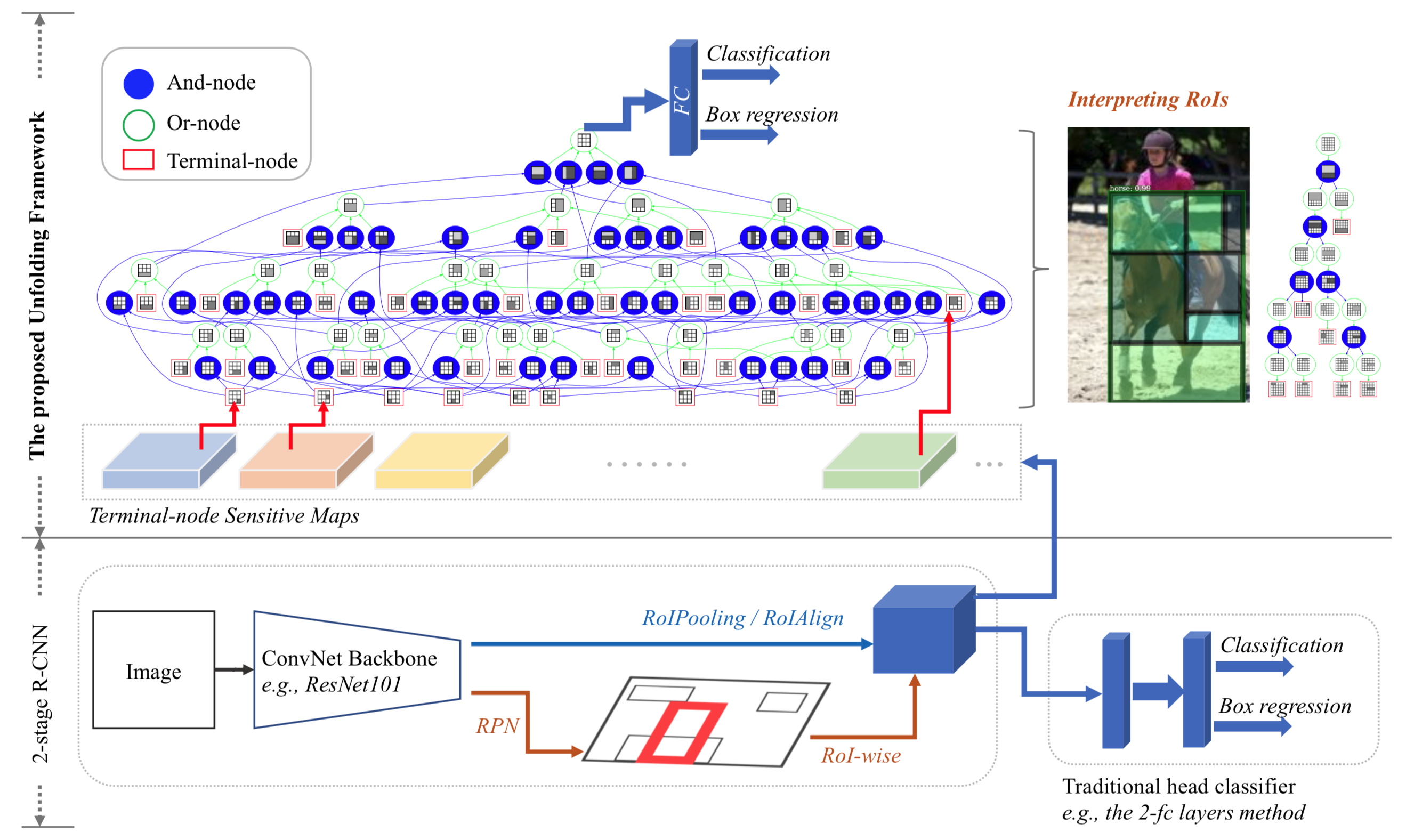
Illustration of the proposed framework
Unfolding latent structures of Region-of- Interest (RoI) is realized by a generic top-down grammar model represented by a directed acyclic AND-OR Graph (AOG). The AOG can be treated as the counterpart of explicit part representations for the implicit (black-box) flatten and fully-connected layer in the traditional head classifier.

Image Synthesis from Reconfigurable Layout and Style
Illustration of the proposed method. Left: Our model preserves one-to-many mapping for image synthesis from layout and style. Three samples are generated for each input layout by sampling the style latent codes. Right: Our model is also adaptive w.r.t. reconfigurations of layouts (by adding new object bounding boxes or changing the location of a bounding box).
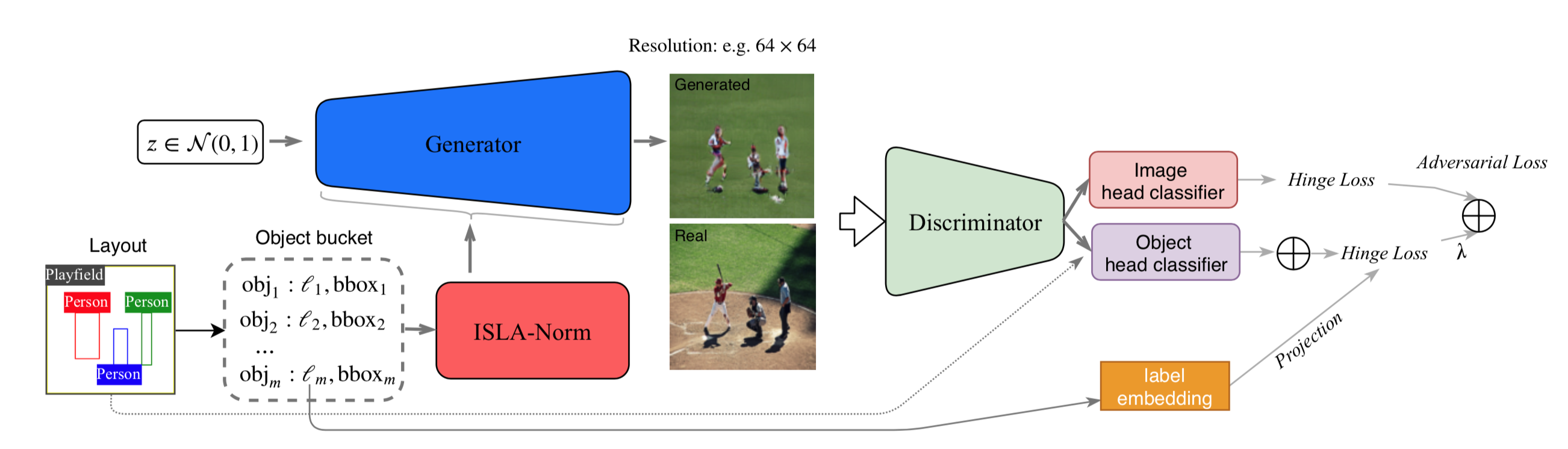
Illustration of the proposed LayOut- and STyle-based GANs (LostGANs) for image synthesis from reconfigurable layout and style.